Las bases de datos desempeñan un papel crucial a la hora de almacenar, organizar y recuperar información. Dos tipos principales de bases de datos son las relacionales (SQL) y las no relacionales (NoSQL). En este artículo, exploraremos las diferencias entre las bases de datos relacionales y no relacionales, sus características y sus ventajas.
¿Qué es una Base de Datos Relacional?
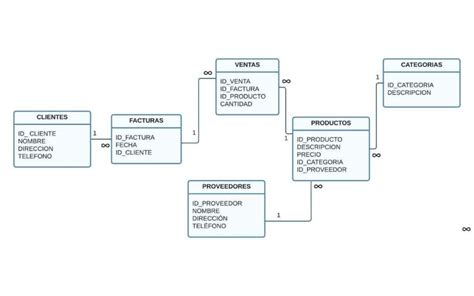
Una base de datos relacional, también conocida como base de datos SQL, es una base de datos que organiza los datos en tablas. Cada tabla contiene registros únicos representados como filas y atributos o propiedades representados como columnas. Estas tablas se relacionan entre sí mediante claves primarias y externas. Con el uso de estas claves, las tablas pueden vincularse entre sí para crear relaciones entre ellas. Por ejemplo, una tabla de clientes y una tabla de pedidos pueden vincularse mediante una clave primaria de ID de cliente en la tabla de clientes y una clave externa de ID de cliente en la tabla de pedidos. Las bases de datos relacionales se utilizan en una amplia gama de aplicaciones, desde sistemas a pequeña escala hasta grandes aplicaciones empresariales.
Conceptos Básicos del Modelo Relacional
Tablas, Filas y Columnas
La estructura fundamental del modelo relacional es la organización de los datos en tablas, filas y columnas. Las tablas son estructuras de datos bidimensionales creadas para mostrar una colección de datos relacionados, organizados de manera lógica para permitir la ejecución de consultas estructuradas.
- Las filas (tuplas) representan entidades o registros específicos en una tabla de base de datos relacional y contienen el valor de cada columna.
- Las columnas representan las categorías de atributos de cada registro en una fila.
En esencia, las columnas definen la estructura y las filas proporcionan los datos reales. Una tabla de productos sencilla podría incluir las siguientes filas de productos específicos con columnas de atributos asociados:
| ID de Producto | Nombre del Producto | Tipo de Producto | Precio ($) |
|---|---|---|---|
| PSHL16 | Salchicha de cerdo picante de Chuck | Salchichas de cerdo picantes (1 lb) | 5.99 |
| PSML16 | Salchicha de cerdo suave de Chuck | Salchichas de cerdo suaves (1 lb) | 5.99 |
| GTS16 | Salchicha de pavo molido de Chuck | Carne de pavo molido sazonado (1 lb) | 6.59 |
| GT48 | Pavo molido de Chuck | Pavo molido (3 lb) | 18.59 |
Esquema y Datos Estructurados
El esquema de una base de datos relacional describe su estructura. Define un plan de cómo deben ser los datos y las reglas que debe seguir. Los datos estructurados se almacenan en un formato coherente y predecible según ese esquema (filas y columnas con relaciones coherentes que definen qué tipos de datos pueden ir en cada lugar y cómo deben representarse). Un buen esquema proporciona integridad y consistencia de los tipos de datos.
Restricciones e Índices
Puede haber restricciones y reglas al escribir en una tabla. Por ejemplo, se puede establecer que cada columna debe contener valores (NO NULOS) sin duplicados (ÚNICOS), excepto el precio. Esto significa que cada fila tiene los mismos campos y cada campo tiene el mismo significado. Con un esquema estricto, los datos permanecen limpios, las relaciones siguen siendo válidas y las consultas siguen siendo previsibles.
Las bases de datos relacionales también pueden tener índices que agilizan la búsqueda de filas sin necesidad de realizar un escaneo completo de la tabla. Un índice almacena los valores de las columnas y proporciona punteros a las filas de la tabla donde aparecen esos valores. El rendimiento puede ralentizarse al consultar tablas grandes, y la indexación evita tener que escanear cada fila de una tabla.
Las bases de datos almacenan índices en varios tipos de estructuras optimizadas para mejorar la velocidad de recuperación de datos:
- Indexación de árbol B: una estructura de datos común diseñada para manejar grandes conjuntos de datos de manera eficiente para reducir la altura del árbol.
- Tablas hash: estructuras de datos que asignan claves a valores y utilizan una función hash para convertir una clave en un índice donde se almacena el valor correspondiente.
Claves y Relaciones
Las claves son esenciales para garantizar la unicidad, la integridad y la recuperación eficiente de los datos. Identifican de forma única las filas, establecen relaciones entre tablas y evitan la duplicación, lo que forma la columna vertebral del diseño de esquemas relacionales. Los puntos de datos de las tablas se pueden unir con claves comunes, lo que hace posible consultar las tablas para generar reportes. Al utilizar claves comunes, las relaciones pueden ser de uno a uno, de uno a muchos y de muchos a muchos.
Las tablas se conectan con varios tipos de claves:
- Superclaves: conjuntos de uno o más atributos que pueden identificar un registro de forma única.
- Clave candidata: un conjunto mínimo de atributos que pueden identificar un registro de forma única.
- Clave primaria: una clave única que identifica una fila en su tabla.
- Clave alternativa: una clave candidata que no se elige como clave principal.
- Clave externa: una columna que apunta a una clave primaria en otra tabla.
- Clave compuesta: se requiere cuando se necesita una combinación de dos o más atributos para identificar todos los registros de una tabla.
Propiedades Clave de las Bases de Datos Relacionales
Las bases de datos relacionales son grupos de operaciones (transacciones) que funcionan juntas y tienen varias características que las hacen confiables. Estas transacciones siguen un conjunto de reglas denominadas ACID:
- Atomicidad: todas las actualizaciones deben finalizarse completamente.
- Consistencia: Las reglas siempre se aplican.
- Aislamiento: las transacciones concurrentes no interfieren con los estados intermedios de cada una.
- Durabilidad: una vez comprometidos, los datos pueden sobrevivir a fallas o interrupciones.
Estas reglas ayudan a garantizar la integridad de los datos a nivel transaccional, lo que asegura que las operaciones de la base de datos se completen de manera confiable y correcta. El diseño del esquema, los tipos de datos y las restricciones se encargan de garantizar que los valores de las columnas sean atómicos y coherentes en su significado. Las restricciones se utilizan para mantener la coherencia entre varias tablas.
Otra propiedad clave de las bases de datos relacionales es el lenguaje de consulta estructurada (SQL), el lenguaje más común para extraer datos. Dado que los datos se almacenan en tablas predecibles con relaciones, se utiliza SQL para responder de manera eficiente a preguntas complejas y ayudar a analizar los datos. Ofrece un método estándar para ejecutar consultas, recuperar datos, insertar, actualizar o eliminar registros, crear bases de datos o tablas nuevas y establecer permisos en tablas, procedimientos y vistas.
Las bases de datos relacionales también deben garantizar la seguridad y el control de acceso para proteger los datos en varios aspectos:
- Autenticación: Quién accede a la base de datos.
- Autorización: Qué se permite hacer.
- Auditoría: Confirmación de lo que se hizo y cuándo.
La seguridad de las bases de datos también incluye características como el cifrado y el respaldo y la recuperación para que los datos no se pierdan durante fallas del sistema.
Las bases de datos relacionales se convirtieron en los “sistemas de registro” predeterminados debido a su estandarización y madurez. La estandarización también aumenta la competencia y las opciones entre los proveedores.
Normalización de Bases de Datos
Normalizar una base de datos es organizar la información con el objetivo de evitar duplicidades innecesarias, garantizar la mayor estabilidad y asegurar la mínima redundancia. Los datos constituyen hoy en día el auténtico poder para las empresas, ya que en ellos basan gran parte de sus decisiones. Por este motivo, uno de sus mayores retos es conseguir ordenarlos y extraer de ellos la información que precisan de la forma más sencilla. La creación de un sistema que organice y estandarice la información de forma efectiva en las bases de datos es lo que se conoce como normalizar la base de datos, un procedimiento imprescindible para conseguir que estas sean fiables y estables.
¿Qué es la Normalización?
Normalizar una base de datos implica llevar a cabo toda una serie de acciones con el fin de organizar la estructura de dicha base de datos de una manera eficiente, es decir, eludiendo que se produzcan posibles redundancias de información y evitando que puedan generarse anomalías mientras se manipulan los datos. Esta tarea se basa en unas reglas llamadas formas normales, a través de las que se establecen criterios que consiguen ordenar correctamente los datos.
Para llevar a cabo la normalización de una base de datos, será preciso dividir las tablas en estructuras más pequeñas, que puedan relacionarse entre ellas. Así, cada tabla habrá de contar con una función específica y contener datos también vinculados entre sí. Este objetivo se consigue mediante la eliminación de redundancias y la reducción de dependencias entre los datos. Asegurarse de que todos los campos y registros de las tablas se encuentran ordenados y organizados de forma lógica resulta imprescindible cuando se normaliza una base de datos. De esta forma, su uso es más eficiente y se facilita el procedimiento para actualizar los datos.
Ventajas de la Normalización
Las ventajas que conlleva aplicar las formas normales pasan por:
- Se reduce la redundancia: Se consigue que la información esté ordenada de forma eficiente, por lo tanto, es más sencillo evitar que se dupliquen datos. Así, además de mejorar la consistencia de esos datos, se reduce el espacio de almacenamiento.
- Es más flexible y escalable: Cuando una base de datos está correctamente normalizada, se puede ampliar fácilmente en el momento que así se requiera. También es más sencillo modificarla en caso de ser preciso.
- Aumenta su integridad: El hecho de ampliar las formas normales al proceso de normalización de la base de datos hace que esta cuente con una organización totalmente lógica de la information, haciendo mucho más fácil cualquier búsqueda.
Tipos de Formas Normales
Las formas normales vendrían a ser como las reglas que fijan la organización de los datos y que tienen por misión ordenar la información. Cuando se inicia un proceso de normalización de bases de datos, las formas normales son los pasos consecutivos que deben darse necesariamente.
- Forma 1 (1NF): Es la forma más básica de organización. Requiere que cada columna en una tabla contenga valores atómicos (valores que no pueden descomponerse en partes más pequeñas). Además, cada tabla debe tener una clave primaria única que identifique de manera unívoca cada fila.
- Forma 2 (2NF): Asegura que cada pieza de información se ubique en el lugar adecuado. Cada columna no clave de una tabla debe valerse completamente de la clave primaria. Esto significa que no puede haber dependencias parciales de la clave primaria en ninguna columna no clave.
- Forma 3 (3NF): Precisa que todas las columnas no clave de una tabla dependan directamente de la clave primaria y no de otras columnas no clave. Se trata de asegurar que no haya información innecesaria o redundante en la base de datos. Si una información puede ser determinada por otra pieza de la información que no es la clave principal, entonces no se precisa en la tabla actual.
- Forma 4 (4NF): Garantiza que la base de datos esté lo más limpia y ordenada posible, asegurándose de que no exista información innecesaria o duplicada. Si hay partes de la información que pueden ser separadas, se dividen para que todo esté bien organizado.
- Forma 5 (5NF): Es el nivel experto de la organización de una base de datos porque al utilizarla es posible asegurarse de que no haya ninguna información que pueda dividirse en partes más pequeñas sin perder su significado.
Cada una de las formas normales establece requisitos específicos para la correcta organización de los datos en una base de datos relacional, lo que garantiza la eficiencia, coherencia e integridad de los datos almacenados.
¿Cómo Normalizar una Base de Datos?
Para normalizar una base de datos se pueden seguir los siguientes pasos:
- Identificar las tablas y las relaciones entre ellas.
- Aplicar la primera forma normal garantizando que cada tabla tenga una clave primaria única y que cada columna contenga valores atómicos.
- Aplicar la segunda forma normal permitiendo que no haya dependencias parciales de la clave primaria en las columnas no clave.
- Continuar aplicando las formas normales subsiguientes según sea necesario.
Ejemplo de Normalización de Base de Datos
Como ejemplo de normalización, se propone una base de datos para almacenar información sobre estudiantes en una escuela.
Tabla sin normalizar:
Supongamos una tabla simple con la siguiente información de estudiantes:
| ID Estudiante | Nombre Estudiante | Curso | Profesor | Teléfono Profesor |
|---|---|---|---|---|
| 101 | Ana García | Matemáticas | Dr. Pérez | 555-1234 |
| 102 | Luis Fernández | Física | Dra. López | 555-5678 |
| 101 | Ana García | Química | Dr. Pérez | 555-1234 |
Aplicando las Formas Normales:
- Primera forma normal (1FN): En este caso, todos los valores ya son atómicos y del mismo tipo, así que esa tabla ya se encuentra en 1FN.
- Segunda forma normal (2FN): Se necesita identificar una clave primaria y verificar que cada atributo dependa completamente de esa clave primaria. El `ID Estudiante` es único para cada estudiante. Sin embargo, la columna `Profesor` y `Teléfono Profesor` no dependen únicamente del `ID Estudiante` si un estudiante cursa varias materias con el mismo profesor. Para corregir esto, se puede crear una tabla separada para los profesores.
Tabla de Estudiantes (en 2FN):
| ID Estudiante | Nombre Estudiante | ID Curso | ID Profesor |
|---|---|---|---|
| 101 | Ana García | M101 | P001 |
| 102 | Luis Fernández | F202 | L002 |
| 101 | Ana García | Q303 | P001 |
Tabla de Profesores:
| ID Profesor | Nombre Profesor | Teléfono Profesor |
|---|---|---|
| P001 | Dr. Pérez | 555-1234 |
| L002 | Dra. López | 555-5678 |
Tabla de Cursos:
| ID Curso | Nombre Curso |
|---|---|
| M101 | Matemáticas |
| F202 | Física |
| Q303 | Química |
En este punto, la tabla de estudiantes está en 2FN. Para la Tercera Forma Normal (3FN), se trata de asegurar que no haya dependencias transitivas. Si el `Teléfono Profesor` estuviera en la tabla de estudiantes y dependiera de `ID Profesor`, se movería a la tabla de profesores, como ya se hizo.
Este es un ejemplo simple. En situaciones más complejas, pueden ser necesarias más formas normales o ajustes adicionales. La normalización es un proceso importante para garantizar que las bases de datos estén bien organizadas y sean eficientes.
Bases de Datos Relacionales vs. No Relacionales (NoSQL)
Mientras que las bases de datos relacionales se basan en un esquema fijo y tablas estructuradas, las bases de datos no relacionales, o NoSQL, son cada vez más populares por su capacidad para manejar datos no estructurados o semiestructurados. Los datos no estructurados son aquellos que no se ajustan a un modelo o esquema de datos específico, como las publicaciones en redes sociales. Los datos semiestructurados tienen cierta estructura, pero no se ajustan a un esquema rígido.
Tipos de Bases de Datos No Relacionales
Las bases de datos no relacionales están diseñadas para manejar datos no estructurados y semiestructurados. No se basan en un esquema fijo, lo que permite añadir o eliminar datos sin definir previamente un esquema. En su lugar, utilizan una variedad de modelos de datos:
- Bases de datos de grafos: utilizan estructuras gráficas para representar y almacenar datos, optimizadas para manejar relaciones complejas.
- Bases de datos de documentos: almacenan y recuperan datos en forma de documentos (como JSON), ideales para aplicaciones web modernas.
- Bases de datos columnares: almacenan y recuperan datos por columnas en lugar de por filas, ideales para consultas analíticas.
- Bases de datos clave-valor: almacenan y recuperan datos como una colección de pares clave-valor, ofreciendo acceso rápido y eficaz.
¿Cuándo Elegir una u Otra?
Las bases de datos relacionales son una buena opción cuando:
- Los datos tienen un esquema bien definido.
- Hay que garantizar la coherencia de los datos.
- Es necesario realizar consultas complejas.
- Se requiere un fuerte cumplimiento de las transacciones ACID.
Las bases de datos no relacionales son una buena opción cuando:
- Los datos no están estructurados o están semiestructurados.
- Hay que manejar grandes volúmenes de datos.
- Se necesita un alto rendimiento y una baja latencia.
- Se requiere flexibilidad en el esquema de datos.
- La escalabilidad horizontal es una prioridad.
Ventajas y Desventajas
Bases de Datos Relacionales:
- Ventajas: Estructura clara, consistencia de datos garantizada, soporte para consultas complejas, cumplimiento ACID.
- Desventajas: Rigidez del esquema, escalabilidad horizontal más compleja, dificultad para manejar datos no estructurados.
Bases de Datos No Relacionales:
- Ventajas: Flexibilidad del esquema, escalabilidad horizontal, manejo de datos no estructurados, alto rendimiento.
- Desventajas: Menor soporte para consultas complejas, posible inconsistencia de datos (consistencia eventual), curva de aprendizaje.
Ejemplos Populares
- RDBMS (Relacionales): MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server, SQLite, MariaDB.
- NoSQL: MongoDB (documentos), Redis (clave-valor), Cassandra (columnar), Neo4j (grafos).
Optimización y Reducción de Bases de Datos
La reducción de los archivos de datos permite recuperar espacio moviendo páginas de datos del final del archivo a espacio desocupado próximo al principio del archivo. Los datos que se mueven para reducir un archivo se pueden dispersar en cualquier ubicación disponible en el archivo, lo que produce fragmentación de índices y puede reducir el rendimiento de las consultas que buscan un intervalo del índice.
Consideraciones Importantes
- Las operaciones de reducción no deben considerarse una operación de mantenimiento normal.
- El tamaño de la base de datos no puede ser menor que el tamaño mínimo especificado al crearla o la última vez que se estableció explícitamente.
- No se puede reducir una base de datos mientras se está realizando una copia de seguridad de la misma.
- La mayoría de las bases de datos requieren espacio disponible para realizar operaciones diarias normales. Si una base de datos se reduce de forma reiterada y su tamaño vuelve a aumentar, es señal de que el espacio disponible es necesario para las operaciones normales.
- La reducción generalmente aumenta la fragmentación de los índices. Para eliminarla, se puede considerar la posibilidad de volver a generar los índices después de la reducción.
- Las operaciones de reducción en curso pueden bloquear otras consultas, y las consultas en curso pueden impedir que se lleven a cabo las operaciones de reducción.
Opción WAIT_AT_LOW_PRIORITY (SQL Server 2022+)
Introducida en SQL Server 2022, esta opción permite que las operaciones de reducción no obtengan bloqueos necesarios debido a consultas de ejecución prolongada. Si no se pueden obtener los bloqueos, la operación de reducción agota el tiempo de espera después de un minuto y sale sin aviso, lo que evita el bloqueo de otras consultas.
Optimización de Modelos en Power BI
Para los modeladores de datos de Power BI Desktop, es crucial minimizar la cantidad de datos que se cargan en los modelos, especialmente para los modelos grandes:
- Minimizar columnas: Eliminar cualquier columna que no sirva a los propósitos de informes conocidos.
- Minimizar filas: Cargar la menor cantidad de filas posible, filtrando por tiempo (historial de datos) o por entidad (subconjunto de datos).
- Cargar datos resumidos: Resumir métricas de ventas, agrupando por fecha, cliente y producto, puede reducir significativamente el tamaño del modelo, aunque puede limitar el nivel de detalle de los informes.
- Conversión de datos de texto a numéricos: En algunos casos, convertir datos de texto a valores numéricos puede mejorar la compresión.
- Columnas calculadas: Preferir la creación de columnas personalizadas en Power Query siempre que sea posible, ya que las columnas calculadas en DAX suelen lograr una compresión menos eficaz.
- Fecha y hora automáticas: Deshabilitar esta opción si no se utiliza para evitar la creación de tablas de fecha y hora automáticas innecesarias.
- Modo de almacenamiento DirectQuery: Establecer el modo de almacenamiento para tablas de hechos más grandes en DirectQuery puede reducir el tamaño del modelo al no importar datos, sino consultarlos directamente desde el origen.